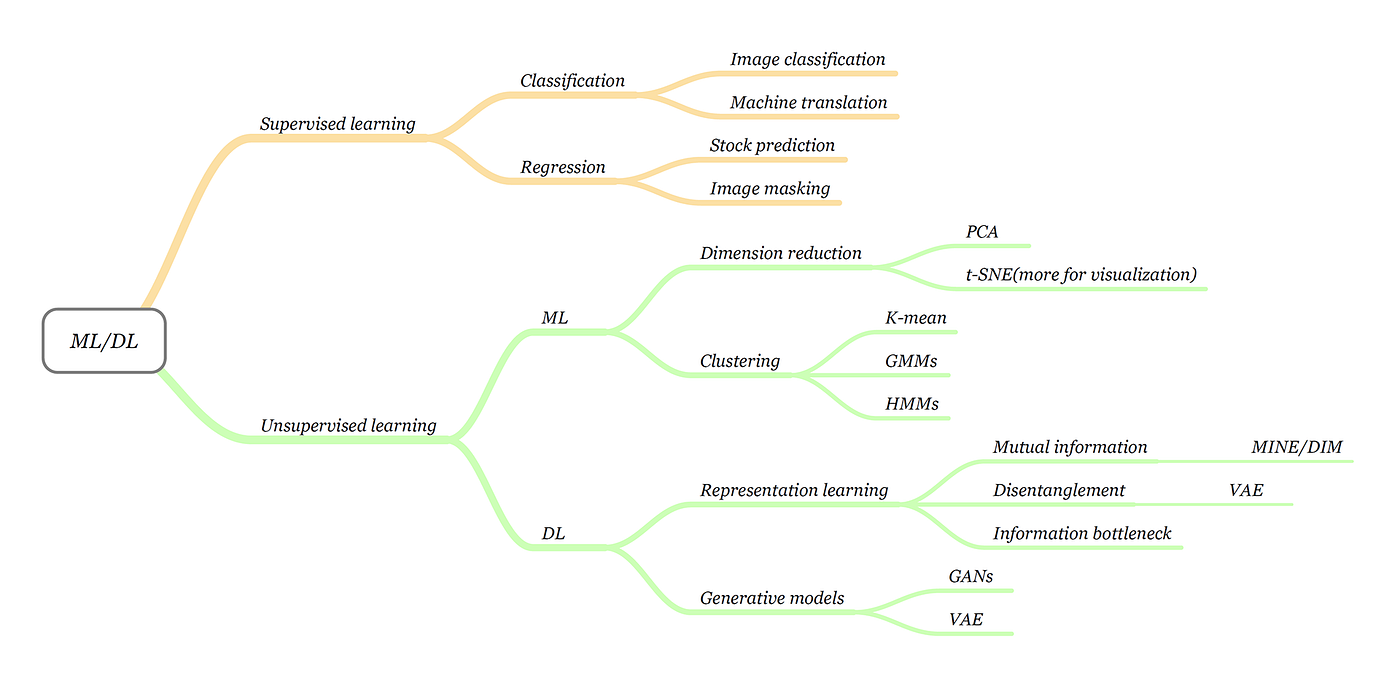
39 in supervised learning class labels of the training samples are known
Supervised Multi-labeling classifier - IBM The Supervised Multi-labeling classifier classifies a document into pre-defined classes and give it labels representing assigned classes to it. A set of classes into which the documents are classified is defined by providing training data, which is a set of documents having correct labels. The document classification predicts types, topics, or ... PDF Supervised Learning: Classificaon - fenyolab.org • The known label of test sample is compared with the classified result from the model • Accuracy rate is the percentage of test set samples that are correctly classified by the model • Test set is independent of training set (otherwise over-fing) • If the accuracy is acceptable, use the model to classify new data
A brief introduction to weakly supervised learning - OUP Academic Abstract. Supervised learning techniques construct predictive models by learning from a large number of training examples, where each training example has a label indicating its ground-truth output. Though current techniques have achieved great success, it is noteworthy that in many tasks it is difficult to get strong supervision information like fully ground-truth labels due to the …
In supervised learning class labels of the training samples are known
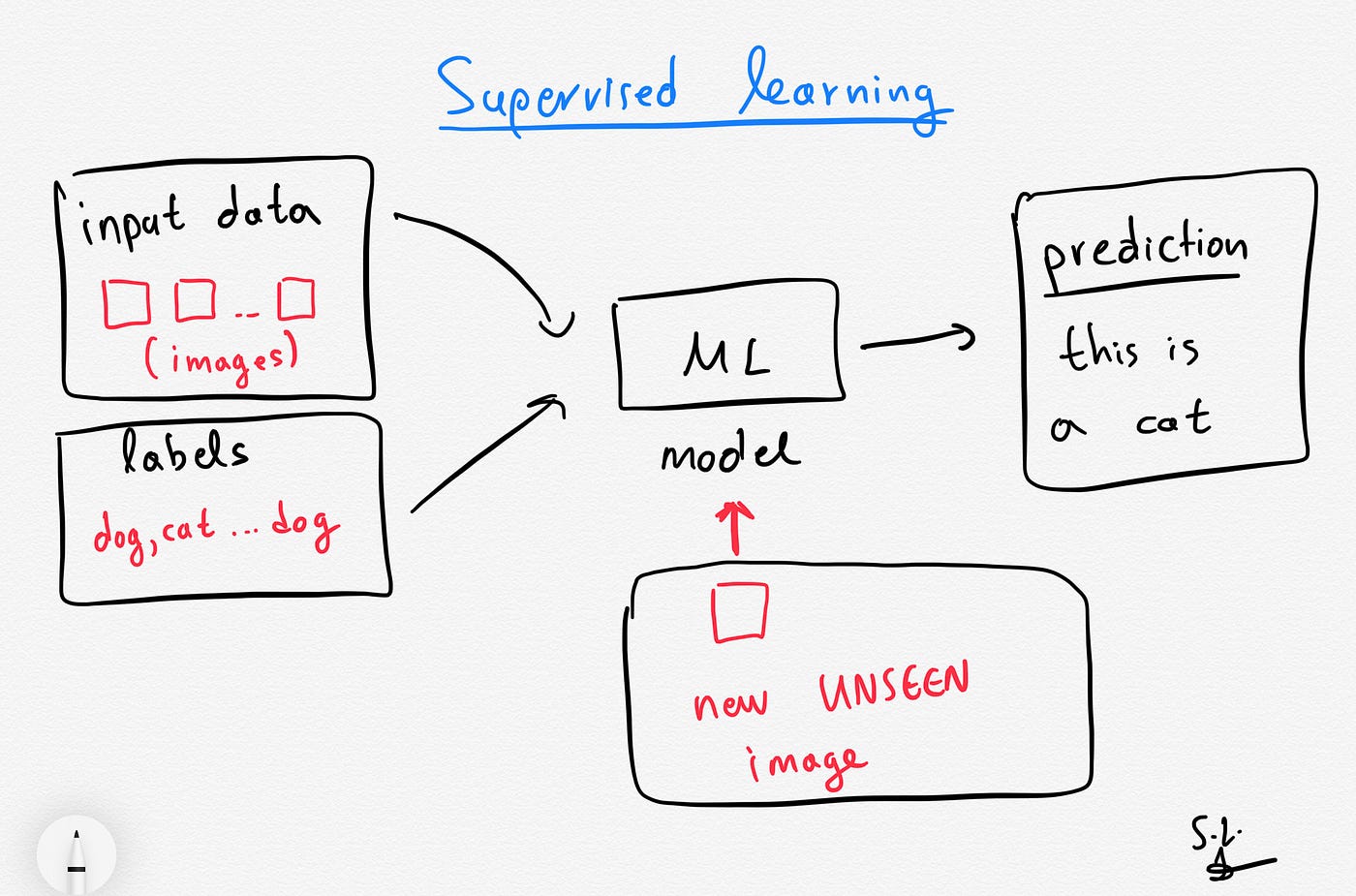
What is Supervised Learning? - tutorialspoint.com Supervised learning, one of the most used methods in ML, takes both training data (also called data samples) and its associated output (also called labels or responses) during the training process. The major goal of supervised learning methods is to learn the association between input training data and their labels. What is Supervised Learning? | TIBCO Software Supervised learning solves known problems and uses a labeled data set to train an algorithm to perform specific tasks. ... algorithms are given training input data with a 'class' label. For example, training data might consist of the last credit card bills of a set of customers, labeled with whether they made a future purchase or not ... Machine Learning Glossary | Google Developers Jul 18, 2022 · A type of supervised learning whose objective is to order a list of items. rank (ordinality) The ordinal position of a class in a machine learning problem that categorizes classes from highest to lowest. For example, a behavior ranking system could rank a dog's rewards from highest (a steak) to lowest (wilted kale). rank (Tensor)
In supervised learning class labels of the training samples are known. API Reference — scikit-learn 1.1.2 documentation API Reference¶. This is the class and function reference of scikit-learn. Please refer to the full user guide for further details, as the class and function raw specifications may not be enough to give full guidelines on their uses. For reference on concepts repeated across the API, see Glossary of Common Terms and API Elements.. sklearn.base: Base classes and utility functions¶ Supervised Learning - an overview | ScienceDirect Topics Linear Regression. Linear regression is a supervised learning technique typically used in predicting, forecasting, and finding relationships between quantitative data. It is one of the earliest learning techniques, which is still widely used. For example, this technique can be applied to examine if there was a relationship between a company’s advertising budget and its sales. EOF en.wikipedia.org › wiki › Decision_tree_learningDecision tree learning - Wikipedia Decision Tree Learning is a supervised learning approach used in statistics, data mining and machine learning.In this formalism, a classification or regression decision tree is used as a predictive model to draw conclusions about a set of observations.
Semi-Supervised Learning, Explained | AltexSoft Semi-supervised learning bridges supervised learning and unsupervised learning techniques to solve their key challenges. With it, you train an initial model on a few labeled samples and then iteratively apply it to the greater number of unlabeled data. Unlike unsupervised learning, SSL works for a variety of problems from classification and ... What is Supervised Learning? | IBM What is supervised learning? Supervised learning, also known as supervised machine learning, is a subcategory of machine learning and artificial intelligence. It is defined by its use of labeled datasets to train algorithms that to classify data or predict outcomes accurately. en.wikipedia.org › wiki › Supervised_learningSupervised learning - Wikipedia Supervised learning (SL) is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples . [2] Self-supervised learning in medicine and healthcare - Nature Aug 11, 2022 · Self-supervised learning is a better method for the first phase of training, as the model then learns about the specific medical domain, even in the absence of explicit labels.
PDF Supervised Learning in Absence of Accurate Class Labels: a Multi ... samples and corresponding labels associated with that data. The goal of building a classifier is then to find a suitable boundary that can predict correct labels on test or unseen data. A lot of research has been carried out to build robust supervised learning algorithms that can battle the challenges of nonlinear separations, class imbalances etc scikit-learn.org › supervised_learningSupervised learning: predicting an output variable from high ... Supervised learning consists in learning the link between two datasets: the observed data X and an external variable y that we are trying to predict, usually called “target” or “labels”. Most often, y is a 1D array of length n_samples . Supervised Learning: Basics of Classification and Main Algorithms Based on the features of the training set, the decision tree learns a series of questions to infer the class labels of the samples. The starting node is called the tree root, and the algorithm will split the dataset on the feature that contains the maximum Information Gain iteratively, until the leaves (the final nodes) are pure. Supervised vs Unsupervised Learning Explained - Seldon Examples of supervised learning classification. A classification problem in machine learning is when a model is used to classify whether data belongs to a known group or object class. Models will assign a class label to the data it processes, which is learned by the algorithm through training on labelled training data.
Supervised vs Unsupervised Learning: Difference Between Them
academic.oup.com › nsr › articlebrief introduction to weakly supervised learning | National ... Supervised learning techniques construct predictive models by learning from a large number of training examples, where each training example has a label indicating its ground-truth output. Though current techniques have achieved great success, it is noteworthy that in many tasks it is difficult to get strong supervision information like fully ...
What is Machine Learning: Supervised, Unsupervised, Semi ...
Supervised learning | Engati A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. An optimal scenario will allow for the algorithm to correctly determine the class labels for unseen instances.
The Ultimate Guide to Data Labeling for Machine Learning
Unstructured Data Classification.txt - In Supervised learning, class ... in supervised learning, class labels of the training samples are known select pre-processing techniques from the options all the options a classifer that can compute using numeric as well as categorical values is random forest classifier classification where each data is mapped to more than one class is called multi-class classification tf-idf is …
![What Is Data Labelling and How to Do It Efficiently [2022]](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/60d9ab454dc7ad70f8c5d860_supervised-learning-vs-unsupervised-learning.png)
What Is Data Labelling and How to Do It Efficiently [2022]
Supervised Learning in Absence of Accurate Class Labels Measuring complexity of systems is very important in Cybernetics. An aging human heart has a lower complexity than that of a younger one indicating a higher risk of cardiovascular diseases, pseudo-random sequences used in secure information storage

43 in supervised learning class labels of the training ...
supervised learning and labels - Data Science Stack Exchange 5. The main difference between supervised and unsupervised learning is the following: In supervised learning you have a set of labelled data, meaning that you have the values of the inputs and the outputs. What you try to achieve with machine learning is to find the true relationship between them, what we usually call the model in math.
Self-Updating Models with Error Remediation
› supervised-learningSupervised Learning - an overview | ScienceDirect Topics It contains both quantitative and qualitative variables; the output variable is the label class that Supervised Learning will label the new observations. According to different types of output variables, Supervised Learning tasks can be divided into two kinds: classification task and regression task.

FixMatch: A Semi-Supervised Learning method, that can be ...
[Solved]: Question 84 In Supervised learning, class labels # In supervised learning, class labels of the training samples are "known." • The correct answer is "known." # Supervised learning uses a training set to teach models to yield the desir
Deep learning with noisy labels: exploring techniques and ...
Types Of Machine Learning: Supervised Vs Unsupervised Learning Supervised learning is learning with the help of labeled data. The ML algorithms are fed with a training dataset in which for every input data the output is known, to predict future outcomes. This model is highly accurate and fast, but it requires high expertise and time to build. Also, these models require rebuilding if the data changes.

Machine Learning
› articles › s41551/022/00914-1Self-supervised learning in medicine and healthcare | Nature ... Aug 11, 2022 · Self-supervised learning is a better method for the first phase of training, as the model then learns about the specific medical domain, even in the absence of explicit labels.
![Supervised vs. Unsupervised Learning [Differences & Examples]](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/6158dd5a9eb8a3708b09ee09_3H_KVVErj5hhg3x-6GhSIV7bGYANnhCRyu8LIMmc1179ccxk0B2ZTohkg5o9F8sLioBfeAdVzIJ_H-gsy9jJd5kkLecm6kR6abq5PVA363yILJaF5C7ugbxH0Qye1wYm4aYK0NOR%3Ds0.png)
Supervised vs. Unsupervised Learning [Differences & Examples]
Supervised Learning - C3 AI In supervised classification problems, training examples are often referred to as labels. The following figure shows an example of failure labels and classifier predictions. Figure 6 Time-series representation of a classifier label ("failed" or "not failed") that can be used to train a predictive maintenance machine learning model using ...
The Essential Guide to Quality Training Data for Machine Learning
Supervised learning: predicting an output variable from high ... Supervised learning: predicting an output variable from high-dimensional observations¶. The problem solved in supervised learning. Supervised learning consists in learning the link between two datasets: the observed data X and an external variable y that we are trying to predict, usually called “target” or “labels”. Most often, y is a 1D array of length n_samples.

Top 170 Machine Learning Interview Questions | Great Learning
Supervised learning - Wikipedia A first issue is the tradeoff between bias and variance. Imagine that we have available several different, but equally good, training data sets. A learning algorithm is biased for a particular input if, when trained on each of these data sets, it is systematically incorrect when predicting the correct output for .A learning algorithm has high variance for a particular input if it predicts ...

Semi-supervised Image Classification With Unlabeled Data | Toptal
Dive into Deep Learning 1.0.0-alpha1.post0 documentation - D2L That being said, reinforcement learning can also address many problems that supervised learning cannot. For example, in supervised learning, we always expect that the training input comes associated with the correct label. But in reinforcement learning, we do not assume that for each observation the environment tells us the optimal action.

Supervised vs Unsupervised Learning Explained - Seldon
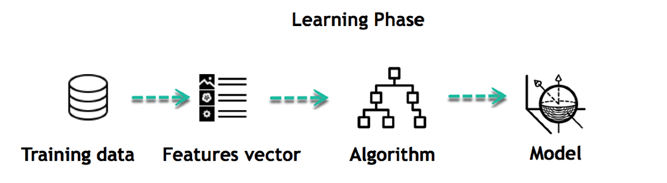
Basics of Supervised Learning (Classification) | by Tarun Gupta ... They are namely Learning and Querying phase. The learning phase consists of two components of namely Induction (training) and Deduction (testing). The querying phase is also known as application phase. Let's talk about it in a more formal way now. Formal definition: Improve over task T, with respect to performance measure P, based on experience E.
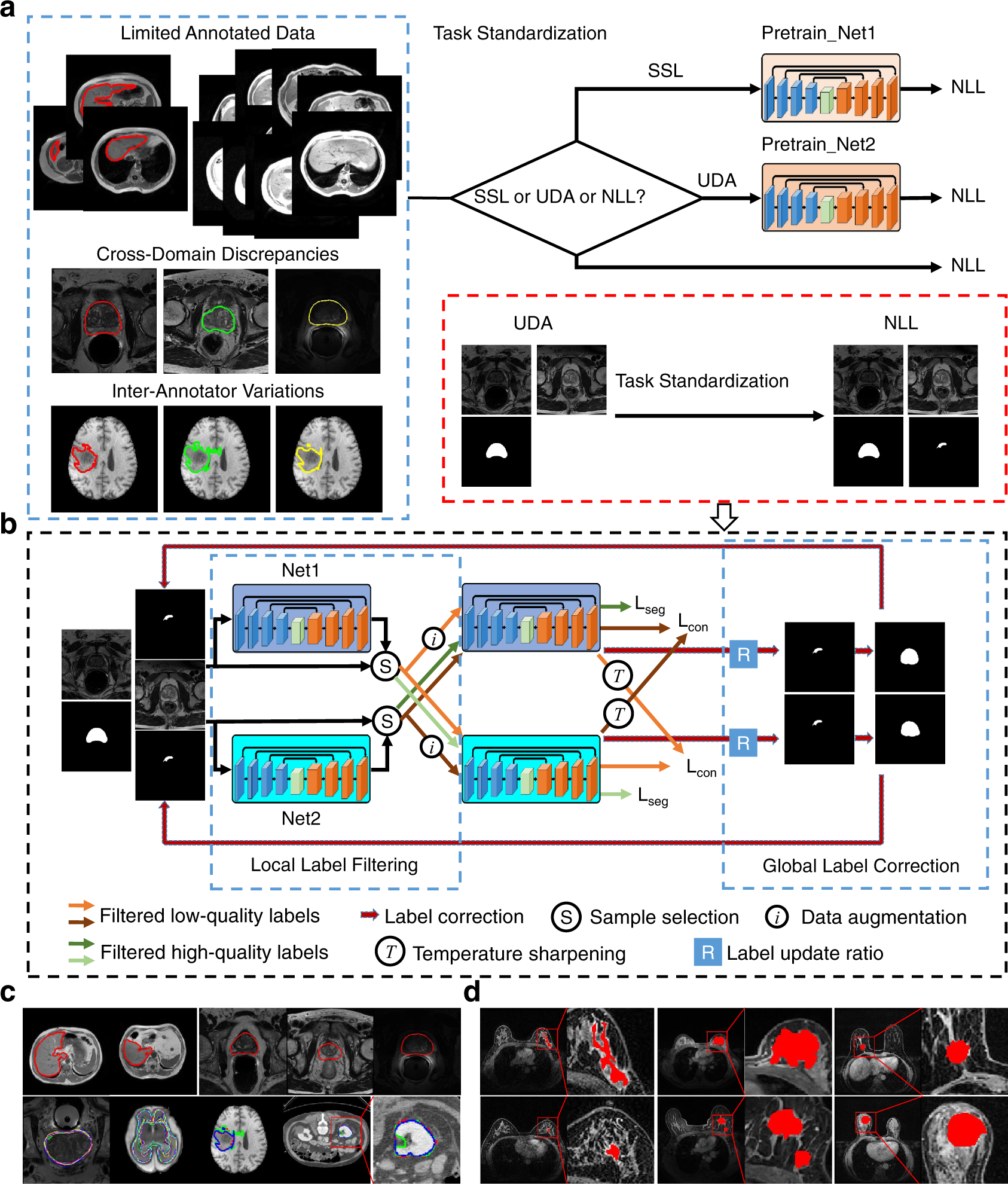
Annotation-efficient deep learning for automatic medical ...
Decision tree learning - Wikipedia Decision Tree Learning is a supervised learning approach used in statistics, data mining and machine learning.In this formalism, a classification or regression decision tree is used as a predictive model to draw conclusions about a set of observations.. Tree models where the target variable can take a discrete set of values are called classification trees; in these tree …
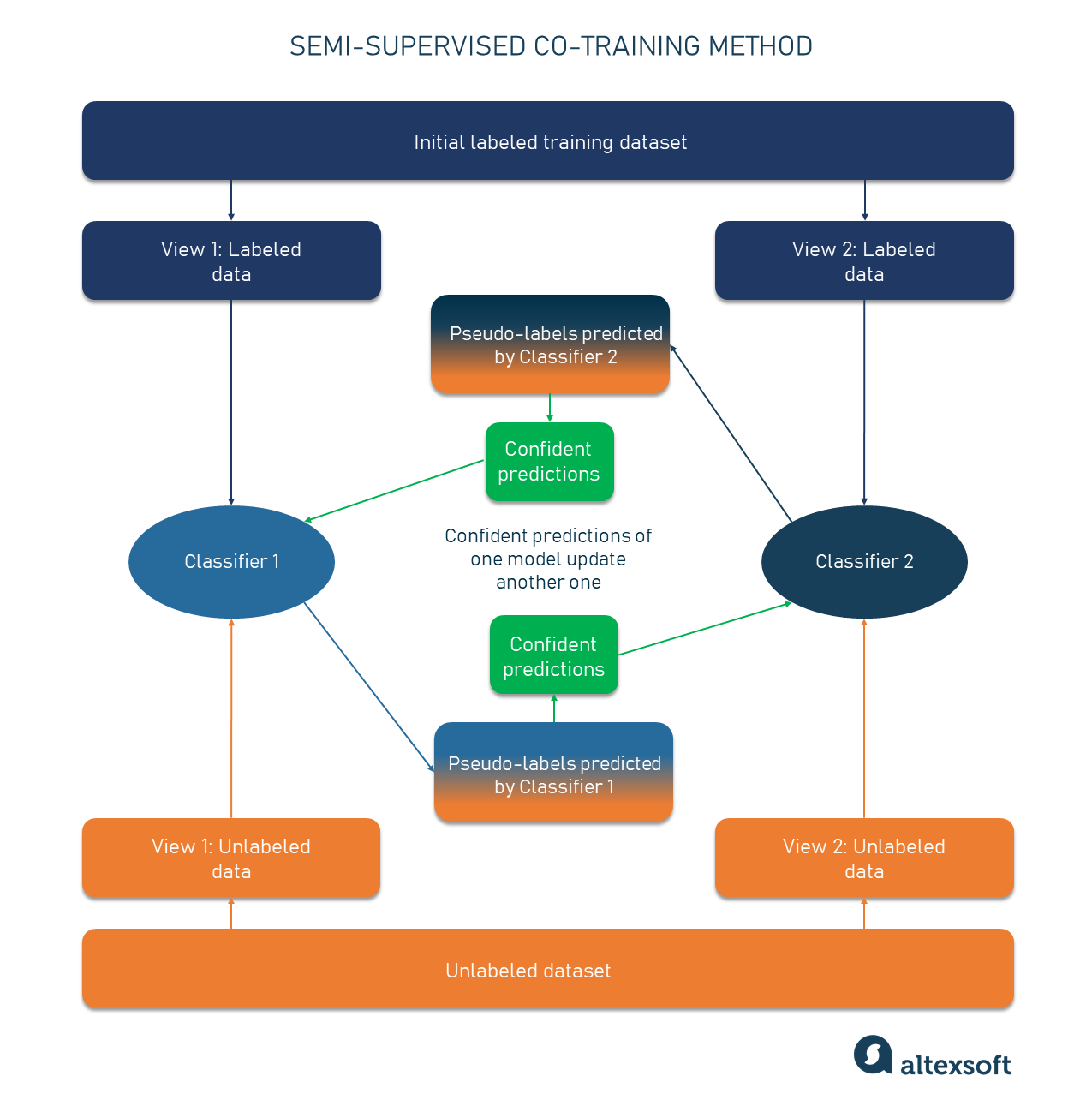
Semi-Supervised Learning, Explained | AltexSoft
Supervised and Unsupervised Machine Learning Algorithms Mar 15, 2016 · You can also use supervised learning techniques to make best guess predictions for the unlabeled data, feed that data back into the supervised learning algorithm as training data and use the model to make predictions on new unseen data. Summary. In this post you learned the difference between supervised, unsupervised and semi-supervised learning.
.png)
Training Data Quality: Why It Matters in Machine Learning
In supervised learning, class labels of the training samples are ... Expert-verified answer scouteo In supervised learning, class labels of the training samples are "known." The correct answer is "known." The other options for the question were "unknown," "partially known," and "doesn't matter." It cannot be "unknown," because training samples must be known.
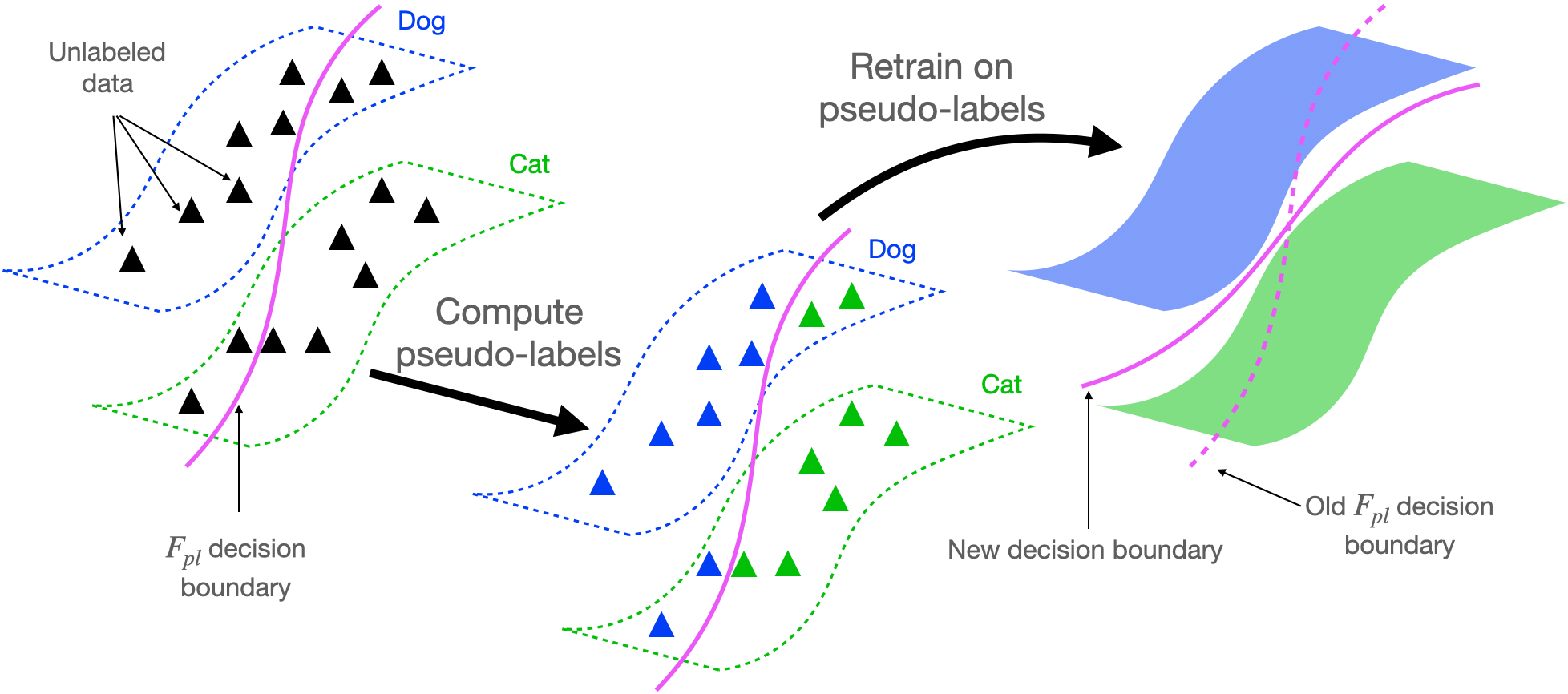
Understanding Deep Learning Algorithms that Leverage ...
scikit-learn.org › stable › modulesAPI Reference — scikit-learn 1.1.2 documentation sklearn.semi_supervised: Semi-Supervised Learning¶ The sklearn.semi_supervised module implements semi-supervised learning algorithms. These algorithms utilize small amounts of labeled data and large amounts of unlabeled data for classification tasks. This module includes Label Propagation. User guide: See the Semi-supervised learning section ...

Supervised learning - Wikipedia
Machine Learning Glossary | Google Developers Jul 18, 2022 · A type of supervised learning whose objective is to order a list of items. rank (ordinality) The ordinal position of a class in a machine learning problem that categorizes classes from highest to lowest. For example, a behavior ranking system could rank a dog's rewards from highest (a steak) to lowest (wilted kale). rank (Tensor)
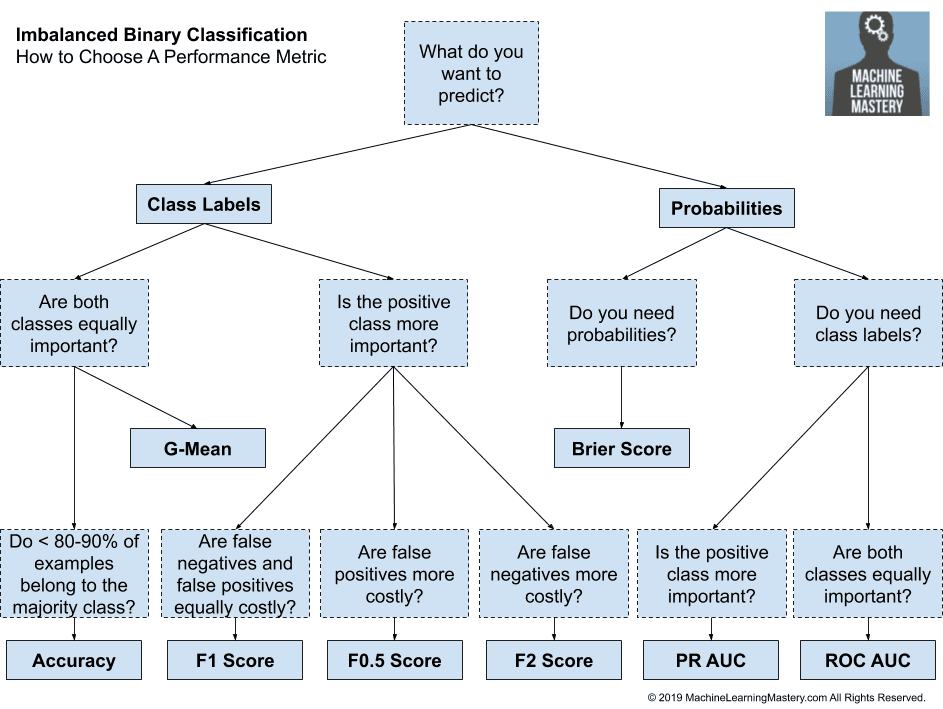
Tour of Evaluation Metrics for Imbalanced Classification
What is Supervised Learning? | TIBCO Software Supervised learning solves known problems and uses a labeled data set to train an algorithm to perform specific tasks. ... algorithms are given training input data with a 'class' label. For example, training data might consist of the last credit card bills of a set of customers, labeled with whether they made a future purchase or not ...
Machine Learning Algorithms For Beginners with Code Examples ...
What is Supervised Learning? - tutorialspoint.com Supervised learning, one of the most used methods in ML, takes both training data (also called data samples) and its associated output (also called labels or responses) during the training process. The major goal of supervised learning methods is to learn the association between input training data and their labels.

Unstructured Data Classification.txt - In Supervised learning ...
Machine Learning: Algorithms, Real-World Applications and ...
Unsupervised Learning and Data Clustering | by Sanatan Mishra ...
Pro Tips: How to deal with Class Imbalance and Missing Labels ...
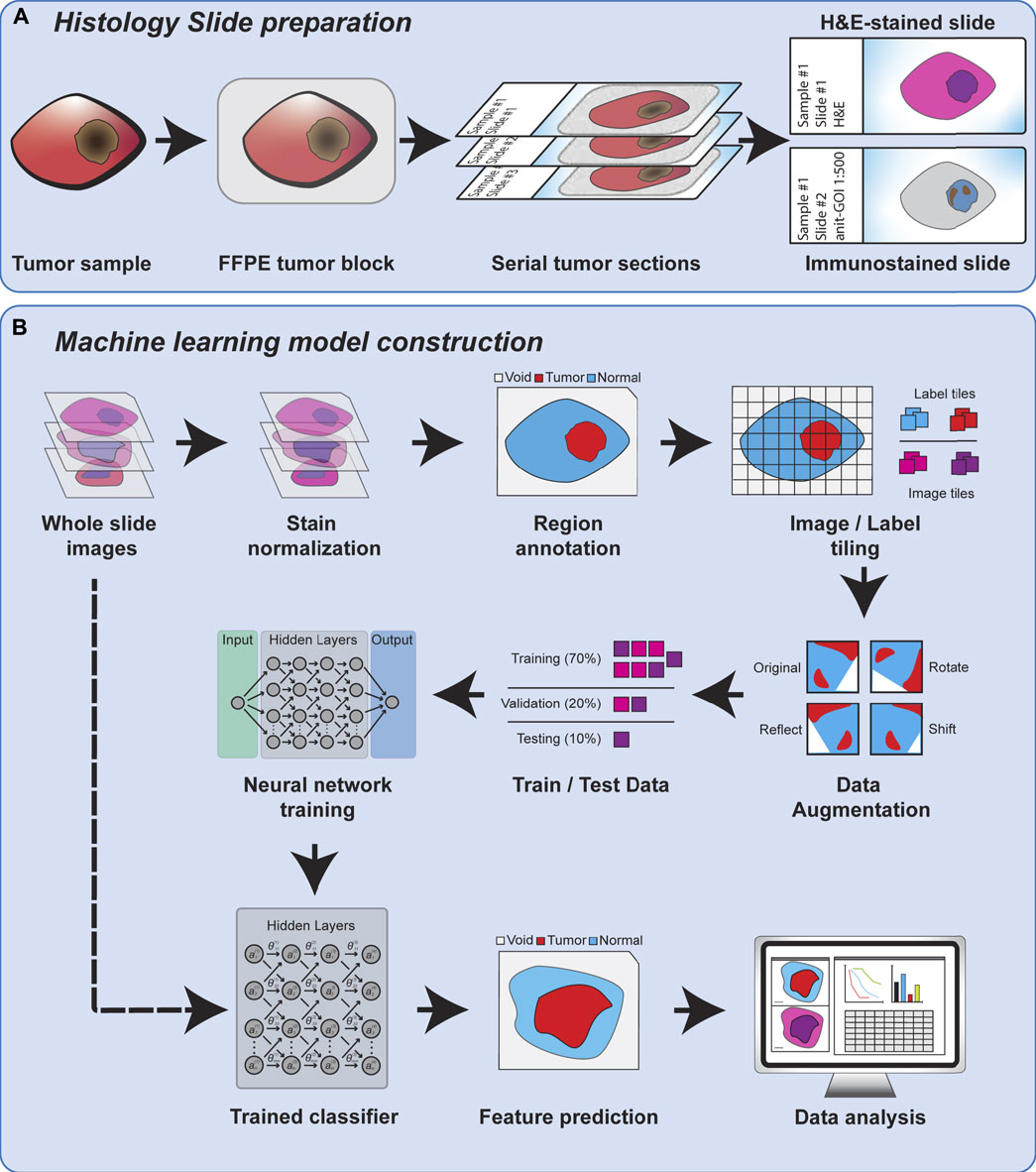
Frontiers | Deep Learning of Histopathology Images at the ...

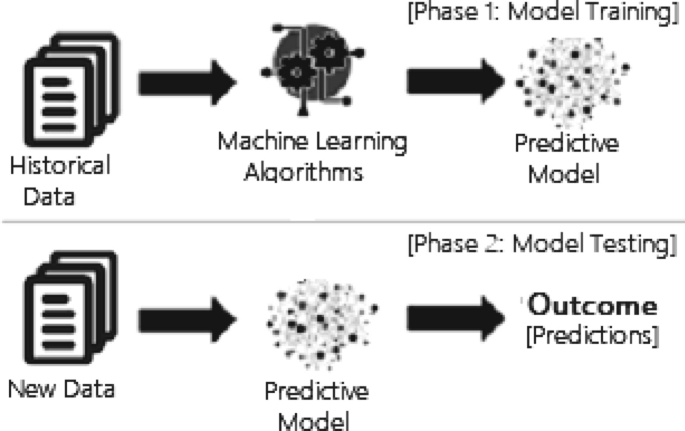
Unsupervised Machine Learning - an overview | ScienceDirect ...

Image Classification | PDF | Statistical Classification ...
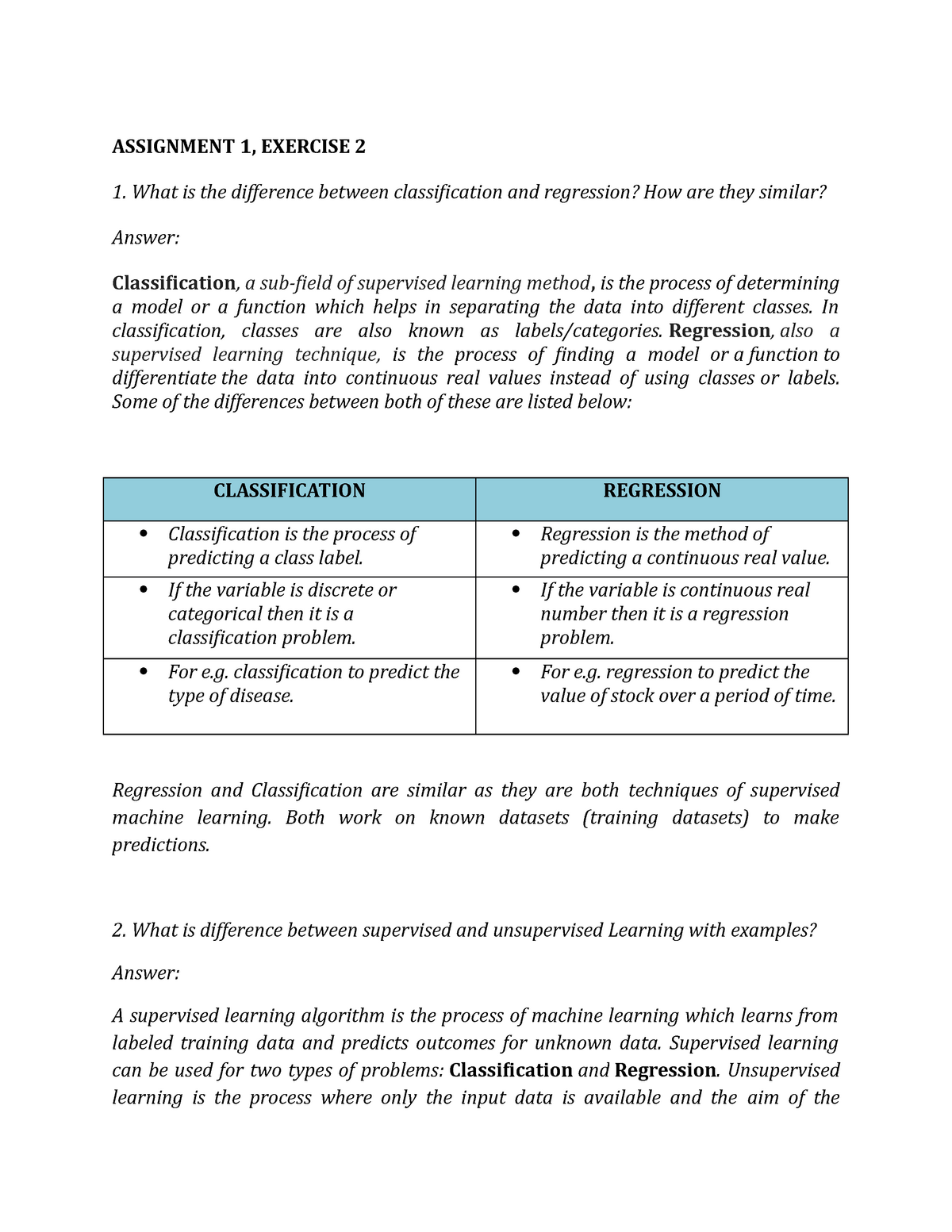
Assign 1ex2 - 2019 Data Mining - ASSIGNMENT 1, EXERCISE 2 ...

Text Classifiers in Machine Learning: A Practical Guide

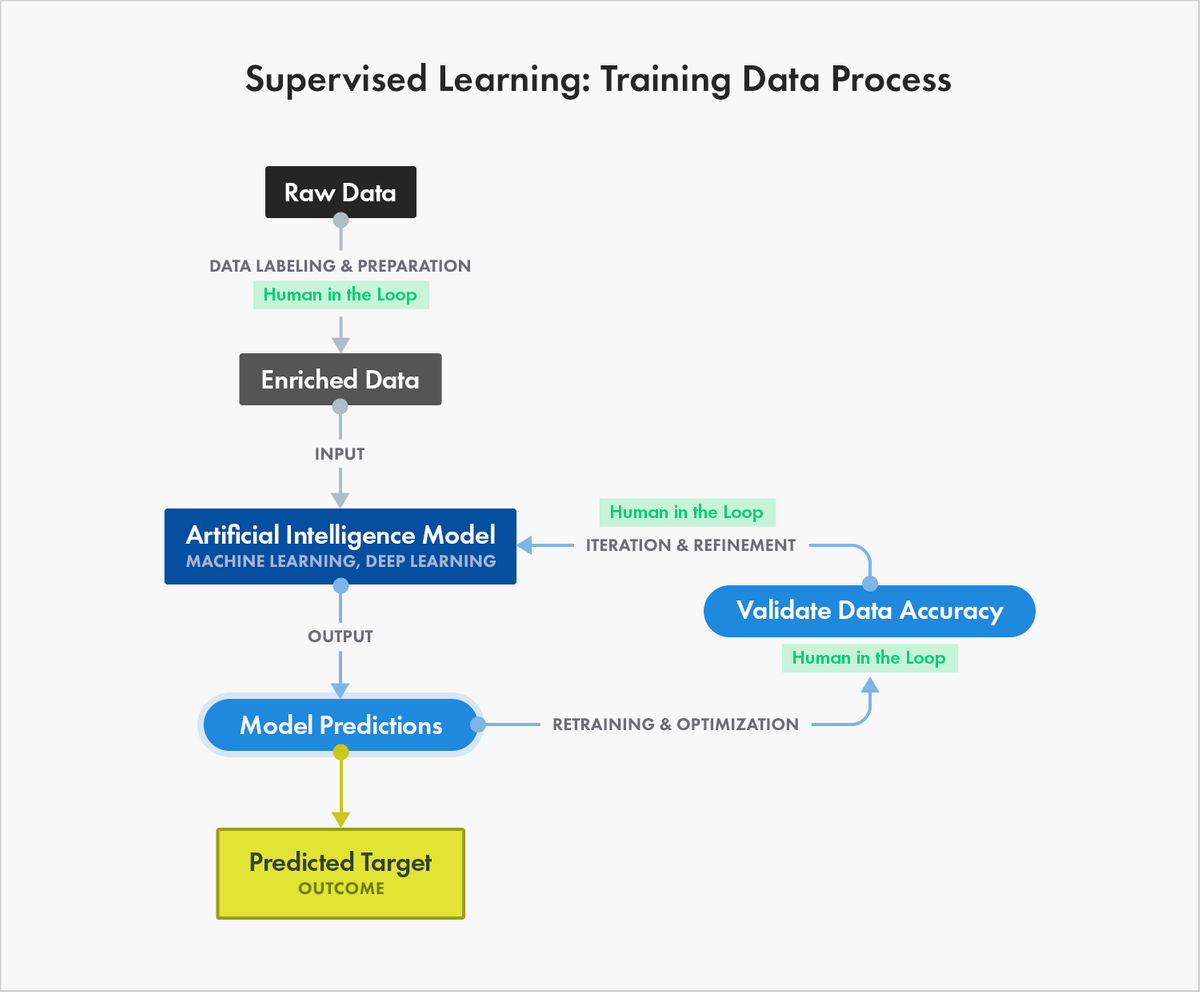
What Is Training Data? How It's Used in Machine Learning

Top 170 Machine Learning Interview Questions | Great Learning

The flowchart of the proposed methodology: (a) Level 1, (b ...

Data Labeling | Data Science Machine Learning | Data Label
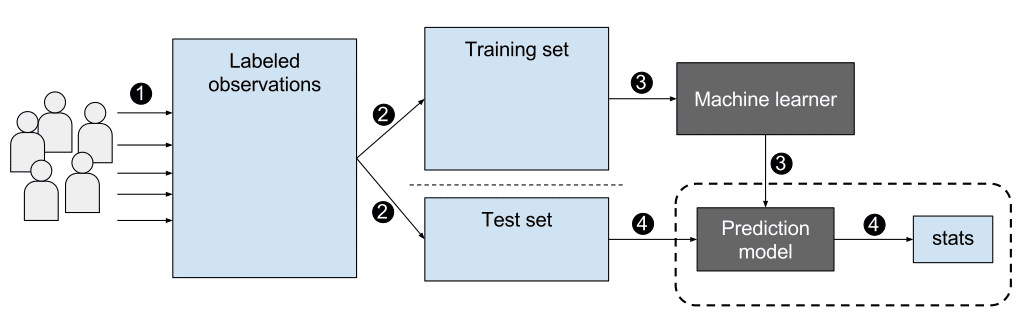
Difference Between Supervised, Unsupervised, & Reinforcement ...

Data Mining – Chapter 3 Classification - ppt download
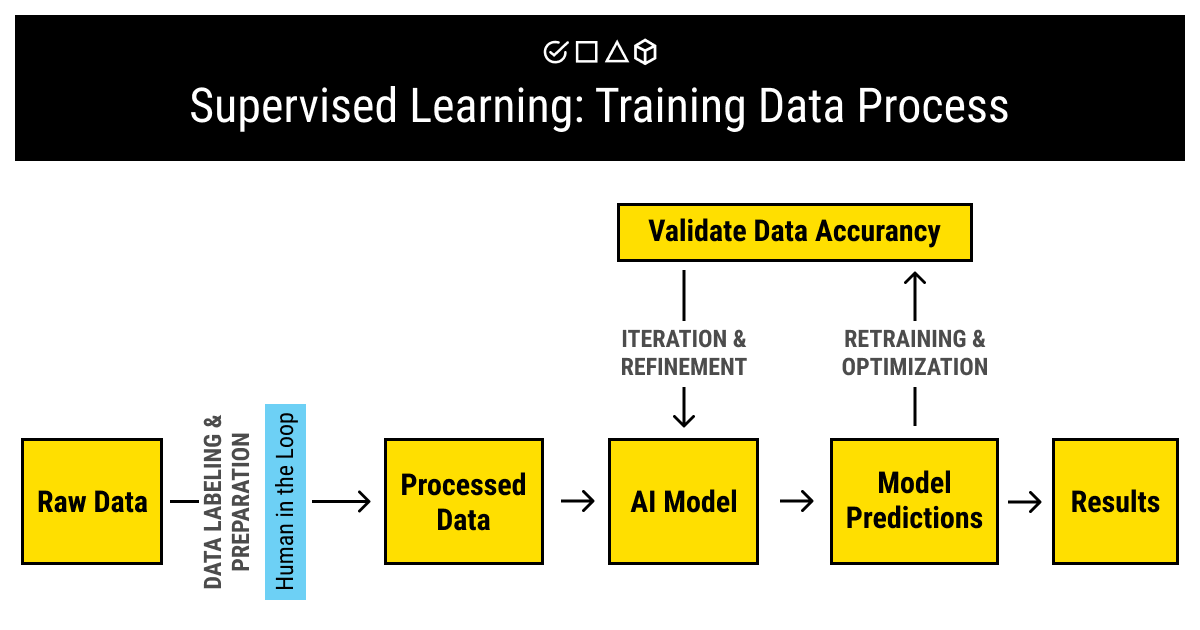
Machine Learning & Training Data: Sources, Methods, Things to ...
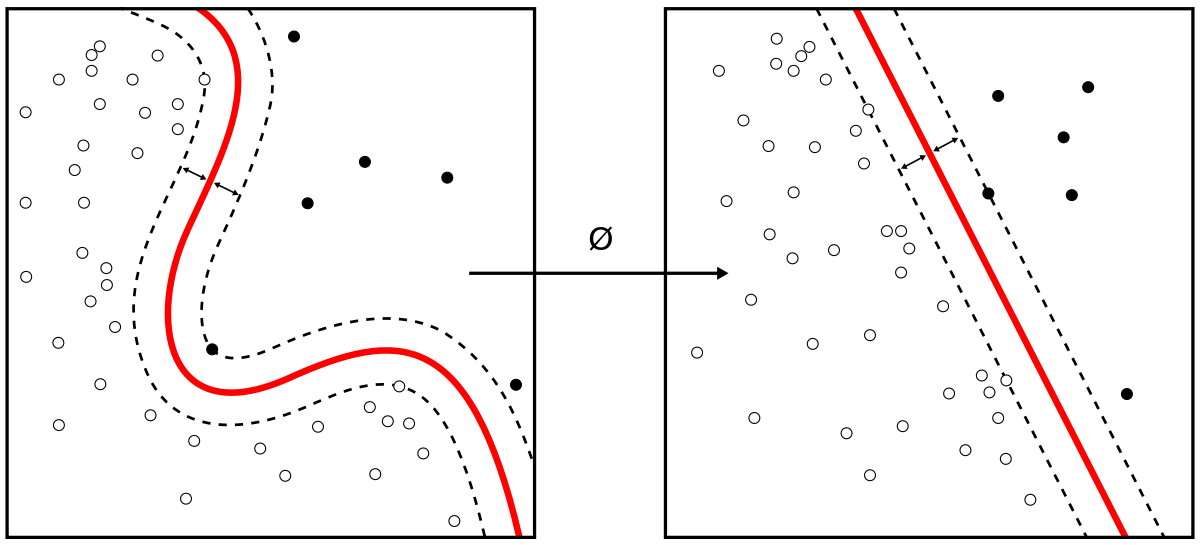
Supervised learning - Wikipedia
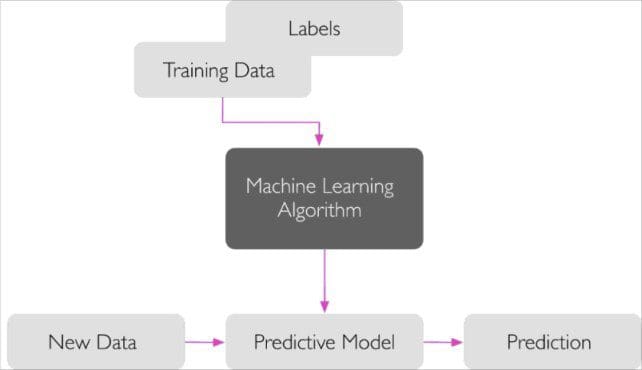
3 different types of machine learning - KDnuggets
Post a Comment for "39 in supervised learning class labels of the training samples are known"